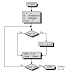
Dynamic Programming (lanjutan)

-> Knapsack 0/1
cth:
i = 1 2 3 4
w = 2 1 3 2
p = 12 10 20 15
M = 5
keterangan:
i = item
w = weight tiap item
p = profit tiap item
M = max weight yang bisa dibawa
output: buat tabel, nilai tabel selanjutnya ditentukan dari nilai tabel sebelumnya

Greedy
1. Minimum Spanning Tree
Spanning tree: graph yg ga ada cycle
1. Algo. Prim
-> selalu nyambung, mulai dari node yang cost nya terkecil, lalu lanjut ke node lain yang jaraknya terkecil dari node sebelumnya
2. Algo. Kruskal
-> urutin dari yang jaraknya terkecil, jangan ambil yang menyebabkan cycle
2. SSSP (Single Source Shortest Path) -> coming soon or coming never, lol
3. Huffman Code
-> merepresentasi karakter dengan variable length
-> representasi karakter yg populer digunakan: ASCII & EBDIC, merupakan representasi dgn fixed length
-> Aturan:
1. Makin sering huruf tsb muncul, makin pendek representasinya -> cth: A bnyk dipake, shg A direpresentasikan sbg 0
2. tidak boleh 1 karakter merupakan awalan dari karakter lain -> cth: A = 0 ; B tdk boleh 01 (karena 0 merupakan A)
-> Contoh membuat representasi berdasarkan aturan berikut:
A > B > C > D
Langkah:
1. ambil 2 huruf terkecil dulu yaitu {C, D}, bedakan dengan 0 & 1
2. gabungkan dgn huruf selanjutnya {B, C, D}, bedakan dgn 0 & 1, dan seterusnya
Dlm bentuk Tree:

Sehingga
A = 0
B = 10
C = 110
D = 111
3. Knapsack Fractional -> barang bs dibagi
Ada 3 macam greedy:
1. Greedy Weight
2. Greedy Profit
3. Greedy Ratio (Profit / Weight) <-- optimal="" p="" selalu="">
Penjelasan:
1. Greedy weight: mengurutkan item yg dimasukkan duluan berdasarkan weight item tsb
logikanya yang weight paling kecil yang dimasukin duluan
2. Greedy Profit: mengurutkan item yg dimasukkan berdasarkan profit. logikanya yg profit terbesar yg dimasukkan duluan
3. Greedy Ratio: mengurutkan item yg dimasukkan duluan berdasarkan rasio dari barang tsb (rasio dapet dari profit / weight)
1. Minimum Spanning Tree
Spanning tree: graph yg ga ada cycle
1. Algo. Prim
-> selalu nyambung, mulai dari node yang cost nya terkecil, lalu lanjut ke node lain yang jaraknya terkecil dari node sebelumnya
2. Algo. Kruskal
-> urutin dari yang jaraknya terkecil, jangan ambil yang menyebabkan cycle
2. SSSP (Single Source Shortest Path) -> coming soon or coming never, lol
3. Huffman Code
-> merepresentasi karakter dengan variable length
-> representasi karakter yg populer digunakan: ASCII & EBDIC, merupakan representasi dgn fixed length
-> Aturan:
1. Makin sering huruf tsb muncul, makin pendek representasinya -> cth: A bnyk dipake, shg A direpresentasikan sbg 0
2. tidak boleh 1 karakter merupakan awalan dari karakter lain -> cth: A = 0 ; B tdk boleh 01 (karena 0 merupakan A)
-> Contoh membuat representasi berdasarkan aturan berikut:
A > B > C > D
Langkah:
1. ambil 2 huruf terkecil dulu yaitu {C, D}, bedakan dengan 0 & 1
2. gabungkan dgn huruf selanjutnya {B, C, D}, bedakan dgn 0 & 1, dan seterusnya
Dlm bentuk Tree:

Sehingga
A = 0
B = 10
C = 110
D = 111
3. Knapsack Fractional -> barang bs dibagi
Ada 3 macam greedy:
1. Greedy Weight
2. Greedy Profit
3. Greedy Ratio (Profit / Weight) <-- optimal="" p="" selalu="">
Penjelasan:
1. Greedy weight: mengurutkan item yg dimasukkan duluan berdasarkan weight item tsb
logikanya yang weight paling kecil yang dimasukin duluan
2. Greedy Profit: mengurutkan item yg dimasukkan berdasarkan profit. logikanya yg profit terbesar yg dimasukkan duluan
3. Greedy Ratio: mengurutkan item yg dimasukkan duluan berdasarkan rasio dari barang tsb (rasio dapet dari profit / weight)